

When I started my programming journey as a kid, my main motivation was that this was the way to teach new things to a computer. I feel like with the advent of machine learning there is now a second way of teaching a machine — or in the case of reinforcement learning even having the machine learn for itself. To find out whether this holds true in practice, I took on the challenge of having an AI learn how to play my mobile game.
Reinforcement Learning
I’ve been fascinated by reinforcement learning since reading about DQN successfully mastering classic Atari games. Back then I spent some time trying to recreate these results by implementing my own Q-learning agent and having it play Atari games in the OpenAI Gym. Without much success. I eventually gave up on it and decided that I not only lack the necessary theoretical background but also the required computing power.
Some time ago now I stumbled upon the existence of an algorithm called PPO (Proximal Policy Optimization) which is supposed to solve a number of issues that DQN tends to have. I don’t claim to fully grasp the differences but from what I’ve gathered PPO is supposed to be more stable and more universally applicable than DQN. Sounded to me like I needed to give reinforcement learning another try. I even had a fitting playground for my new AI in mind.
The Game
I recently wrote a litte mobile game as an experiment. The game is a match 3 type of game (think Bejeweled or Candy Crush) where levels get harder gradually until you’re game over and have to start again at the first level.
The Observation Space
Except for some initial tutorial levels, the core of the game is a board of 7x7 tiles each containing one of the 5 basic colors or one of 7 special items. The number of possible board states lies somewhere between 10³⁴ and 10⁵².

The Action Space
The goal of the game is to group three or more of the same color together in order to create a match. By matching more than three at once you get special items with specific behavior (e.g. arial damage on activation). By allowing an agent to swipe each tile in one of two directions, every possible objective could be achieved, thus requiring an action space of 7x7x2=98 discrete actions. I later realized that the action space can be reduced by 14 to 84 but I did not change my implementation and continued to use the original assumption instead.
Making the Game Playable by a Computer
My game was made to be played by humans not computers. On top of that, it runs on mobile devices. So, how would I be able to take the essence of my game and make it available to a reinforcement learning agent?
I thought about reimplementing the game logic in Python which would have allowed me to easily include it in an OpenAI Gym environment. But then again, although the game mechanics are quite simple, I spent quite a lot of time with the initial implementation which also included quite thorough verification through unit tests. I didn’t want to risk new bugs and a faulty game logic by reimplementing it somewhere else. I needed to know that the game logic is sound before letting an agent try and learn it.
Fortunately, the game is written in Dart, and Dart can be compiled on Desktop computers and servers, too. So, I decided to take the original core game logic and wrap it with a REST API. I would then go ahead and create a Gym environment that uses this API in order to play the game. This would add an overhead for the local HTTP calls but I was willing to try it anyway.
So, this is the resulting architecture:
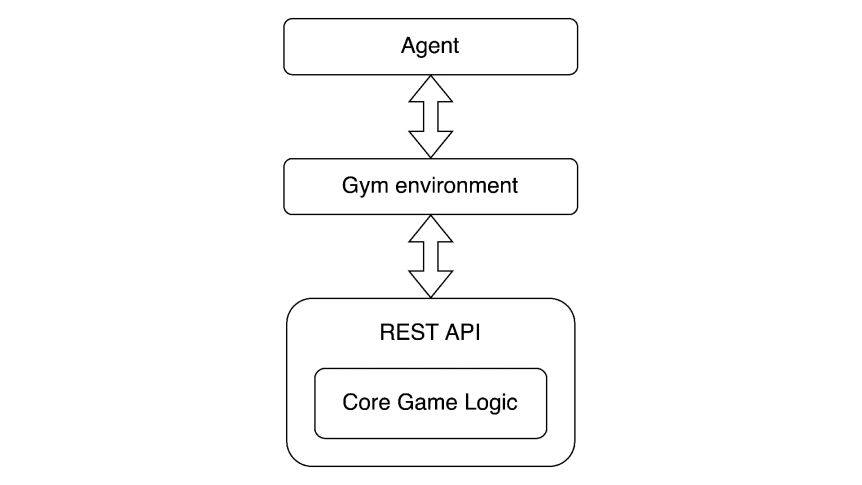
Obtaining a Working PPO Agent
Since my main goal was to see whether I can take an existing PPO implementation and reuse it for my purposes, I had no ambitions of writing my own version of the algorithm this time. That’s why I just took this example PPO from the Keras website that was written to solve the Cart Pole environment from the OpenAI Gym.
After I confirmed that I can also solve the Cart Pole problem with this on my machine, I thought it’s now just a matter of hooking the agent up to my custom Gym environment and let it learn my game. Unfortunately, it wasn’t exactly that simple. As it turns out, there’s a lot of details to think about and also just try what works best.
Things I Learned While Training My Agent
Start Small
When I first hooked up my agent to the game Gym environment, it did not learn at all. So, I decided to drastically reduce the observation space and the action space by letting the agent play a game board of 3x3 tiles with 2 colors only. I also disabled any kind of special items that would only further complicate the game. These changes actually lead to some progress.
Input Encoding
After the first promising results, I figured out that the way observations and rewards are shaped matters a lot. I did a couple of experiments and ended up with a one-hot encoding for the observation space — meaning that each possible tile state gets its own dimension or channel in the input and is either set to 0 or 1. This change alone brought a huge improvement. I also figured out that it’s best to have rewards somewhat centered around 0 and more or less contained between -1 and 1.
Network Architecture
The PPO Cart Pole example used two hidden fully connected layers of size 64 which kind of worked for my reduced game board, too. After experimenting with different network architectures, I found that replacing the first of the two inner layers with two convolutional layers yielded much better results.
All these initial changes and experiments lead to very good results for the 3x3 board with 2 colors. This is what the reward during training looked like:
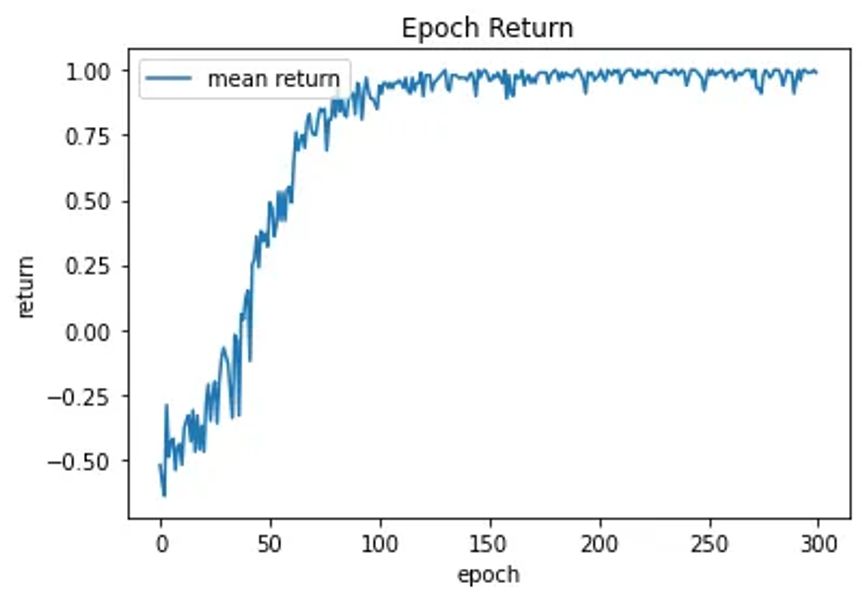
Scaling Is Hard
Now that I had very promising results for this very reduced problem space, it was just a matter of slowly scaling it up and making suitable adjustments to the network architecture and some hyper parameters — or so I thought.
While I was kind of right in making that assumption, it wasn’t easy to figure out what needed to be done in order to make this scale. As I went bigger, I realized that my MacBook Pro could no longer handle the training — I needed to rent GPU time in the cloud which made running experiments very costly. It became clear pretty quickly that the epoch size of 200 draws no longer sufficed to get good results. I eventually settled on an epoch size of 40 000 which made all subsequent experiments taking much more time than the initial ones.
The hardest part was that for the longest time a board of 7x7 with 5 colors just wouldn’t work, no matter what I tried. I first thought that the action space is just too big for a board of this size. Then I tried training for a board of 7x7 with only 4 colors, and it worked just fine. Since the action space depends on the board size and not the number of colors, the size of the action space couldn’t be the issue after all.
I tried messing around with different network architectures, with the number of epochs, with the learning rate and other hyper parameters, and nothing would work.
I was already about to give up when I thought: Let’s just simplify the game again and let the agent just learn the opening move. I modified the game so it would be done after the initial move. This lead to quite good results. I then took a network that was trained in this manner and let it play games that lasted a couple of moves more. Initially the agent’s performance crashed down again but it would slowly learn. After some time, I took this newly trained network and let it play full games. The performance crashed again — yet again it would slowly learn until finally converging in a fairly good state.
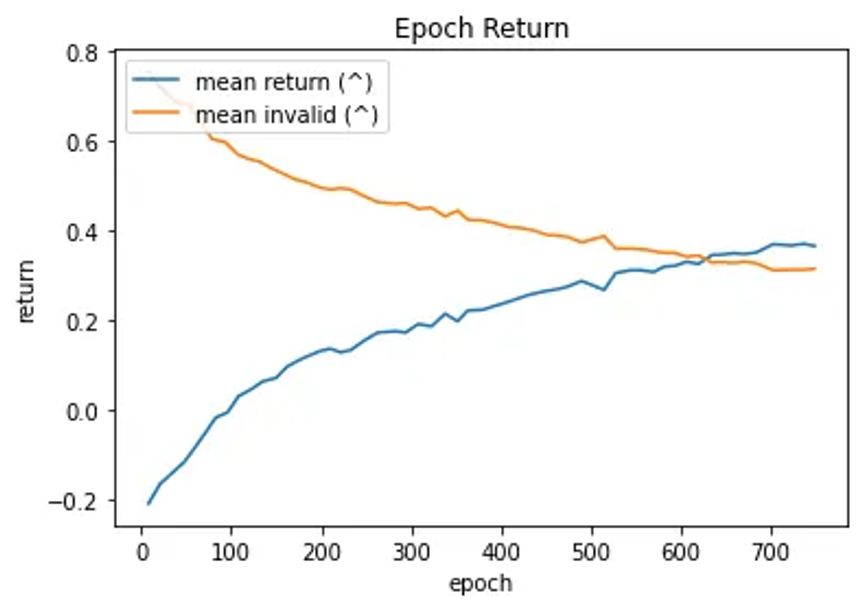
On the chart above you see a smoothed out plot of the final training for a pre-trained network as described above. The plot shows the mean reward for each epoch as well as the mean proportion of invalid draws per epoch. If you were wondering what the final network architecture looked like, this is it:
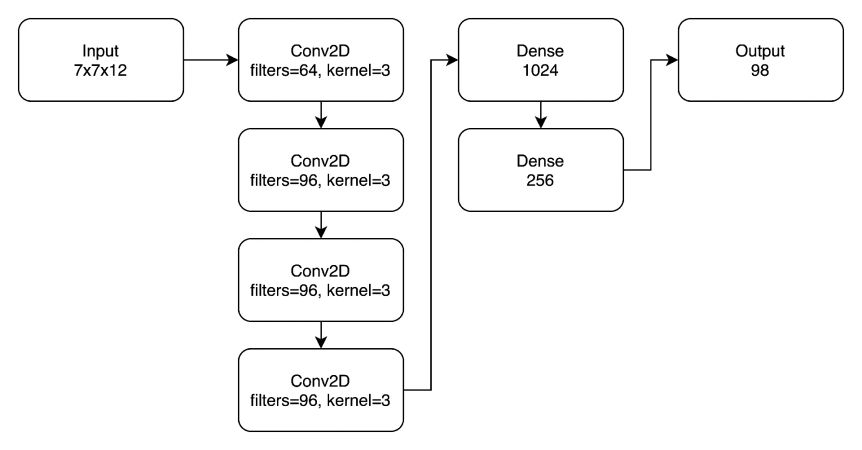
Integrating the Agent Into the Game
Now that I have a trained TensorFlow model for the agent, we want to see it play the game, right?
Fortunately, there’s TensorFlow Lite which lets you port your trained models to your mobile apps. After converting the model to a TensorFlow Lite model and integrating the TensorFlow Lite SDK into my game, I could finally see the agent play my game. So, how does it perform?
Well, not as good as an experienced human player. It still makes obvious mistakes and it doesn’t seem to have fully explored all the game mechanics yet. Also, due to its limited observation space, it doesn’t know about each level’s primary objective which increases its chances to fail a level.
Other than that, it actually plays pretty well. It has even figured out how to use special items to make more damage:

If you’d like to see it for yourself you can download the game called Monster Wipe from Google’s Play Store or Apple’s App Store. Starting from level 6 you get a button at the bottom that activates the AI and has it play automatically.
What Can It Be Used For?
Balancing and Level Design
While using this trained model I already confirmed a suspicion I had for quite some time now: levels 6–15 are too hard compared to what comes after. I could use the AI to accurately determine the difficulty of each level and find a good level progression.
NPC or Opponent
Maybe not for this exact type of game but for similar games an AI like this could be used as an NPC or an opponent that a human player would have to compete with.
Assistant
It’s common practice for games like this to indicate possible next moves to the player in case they’re stuck. A trained AI could be used for this.
Final Thoughts
It was an interesting experience finding out whether I can use reinforcement learning as a software engineer as opposed to a data scientist or a researcher. It’s definitely possible. However, the use case and possible alternative solutions have to be considered carefully as this method takes a lot of time and doesn’t always produce the best results.
If I were to take this even further I’d definitely play around with modifying the reward function, the observation space and the action space. Finding a proper reward function is essential as it determines what the model actually learns. I did modify the reward function a couple of times during my experiments but I always kept it pretty basic.
The observation space could be extended to include the current level’s objectives. The action space, as mentioned before, could be reduced further or maybe even split up in some manner.
However, as running all of these experiments on cloud GPUs got quite expensive in the end, this project will stop here for now.
Besides further training and improving the model, it would also be very interesting to see what kind of patterns the convolutional layers of the neural network have learned to recognize. I may look into ways of visualizing this at some point.